
让不懂建站的用户快速建站,让会建站的提高建站效率!

 你的位置:开云app在线下载入口 > 现金捕鱼 > 开云app在线下载入口 这套题, GPT-5.5、Opus 4.7加起来没考到1分, 东谈主类却拿了满分100?
你的位置:开云app在线下载入口 > 现金捕鱼 > 开云app在线下载入口 这套题, GPT-5.5、Opus 4.7加起来没考到1分, 东谈主类却拿了满分100?


机器之机杼剪部
在大模子「卷生卷死」的今天,群众似乎仍是风俗了模子在各大榜单上刷出靠拢满分准确率。关联词,在一项名为 ARC-AGI-3 的基准测试中,号称当下「最红炸子鸡」的两款顶尖模子 ——OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7,却双双「折戟」……
近日,ARC Prize 官方发布了针对这两款顶级模子的详备分析诠释,兑现令东谈主胆怯:在濒临未见过的逻辑任务时,两者的推崇得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
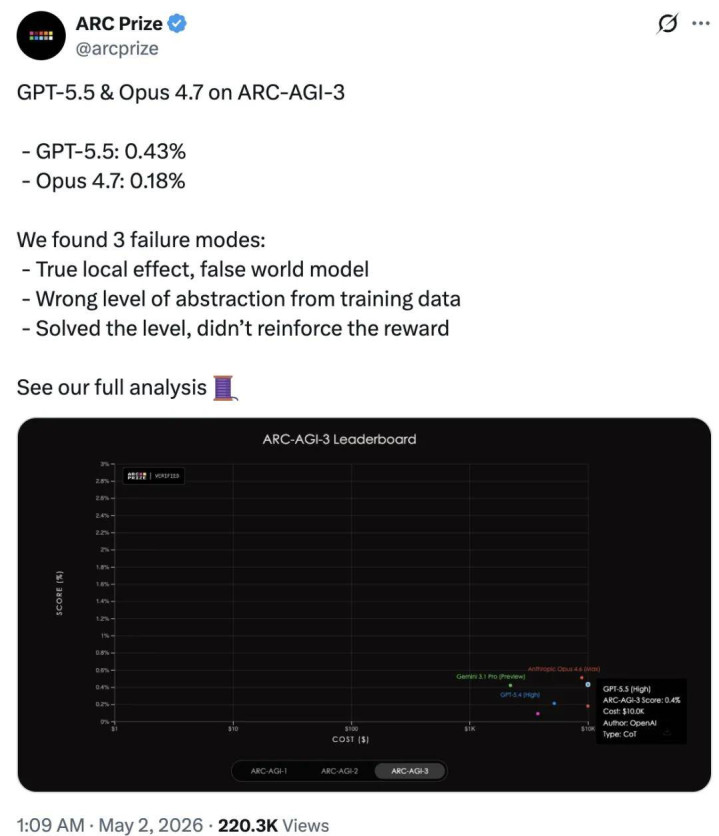
这意味着,即便领有千亿级参数和近乎无尽的算力,这些模子在处理「全新逻辑环境」时的推崇,致使不如一个 6 岁的儿童。
这是怎么一趟事?
ARC-AGI-3:智能的「真伪试金石」
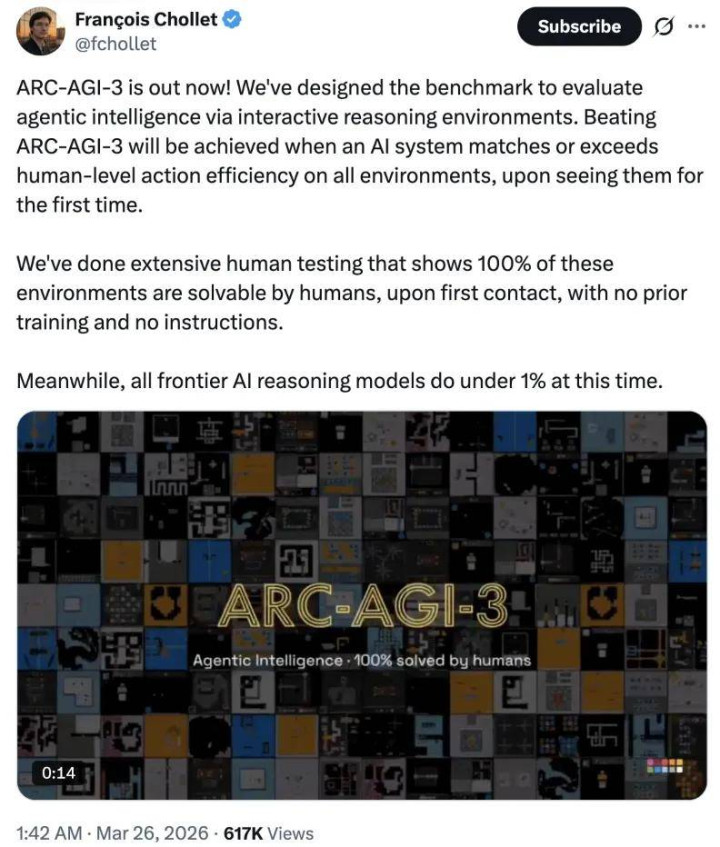
为了更好阐明这一收货,当先咱们来了解一下 ARC-AGI-3,这是由 Keras 之父 François Chollet 创立的基准测试系列的最新一代,于本年 3 月散布。
François Chollet 其时称,当一个 AI 系统在初度斗争通盘环境时,其行动成果概况达到或卓绝东谈主类水平,才算实在「攻克」ARC-AGI-3。
而凭证团队进行的无数的东谈主类测试兑现来看:在莫得任何先验老师、莫得任何证实的情况下,东谈主类在第一次斗争时不错 100% 惩办这些环境中贫乏,与此同期,当今通盘前沿的 AI 推理模子在这一测试上的推崇王人低于 1%。
彼时,OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7 还莫得发布,如今来看,这两个模子也相通难逃这一兑现。
具体来看,ARC-AGI-3 是由 135 个全新环境构成的测试集,每个环境王人由东谈主类手工想象,用来测试模子濒临「未知」的武艺。
关于测试者来说,不管东谈主类照旧 AI,插足环境中将不会赢得任何的玩法证实,要前进,取得进展,必须作念到以下几点:
探索未知界面 ;
从寥落反馈中推断章程(构建宇宙模子) ;
提议并考证假定 ;
从失实中收复 ;
将训戒转移到下一关(执续学习)。
每个环境的构建王人清寒模子频繁依赖的文化学问,只保留「抽象推理武艺自己」。
换句话说,不错把 ARC-AGI-3 阐明为,一个在「新颖性、隐晦性、打算、相宜性」上的最低共同测试聚积,而这些,恰是现实宇宙任务对智能体的中枢条目。因此,ARC-AGI-3 也被公以为当今最接近「东谈主类智能本体」的测试。
顶尖模子纷繁「溃败」背后的三大失败模式
这次,GPT-5.5 和 Claude Opus 4.7 的推崇得分均低于 1% 的收货诚然令东谈主「肉痛」,但比起收货,知谈背后的失败原因似乎更紧要。
ARC Prize 盘问团队通过分析 160 组齐备运行轨迹,包括模子的每一步操作和推理历程,回来出了导致模子「崩溃」的三大中枢失败模式:
一、真的的局部反馈,空虚的宇宙模子
模子概况阐明哪一步行动产生了变化(局部反馈),但无法将这种因果效应改动为一套通用的全局章程。
这是一个最为显著的原因。比如,在一个需要旋转物体以匹配插槽的任务中,模子概况识别出「我按下这个键,物体不错旋转」这一局部礼貌,但它无法将此逻辑飞腾为全局方针,进一步推理出:「旋转会影响兑现,因此我需要在行动前协调物体办法以匹配方针。」
换句话说,模子失败不是因为它们「看不见」,而在于无法把不雅察的事物整合成一个齐备的宇宙模子。
比例,Claude Opus 4.7 在运行任务 「cd82」 时,在第 4 步仍是知道到履行 「ACTION3」 不错旋转容器,随后在第 6 步也不雅察到履行 「ACTION5」 不错倾倒或蘸取油漆。关联词,它永远无法将这些碎屑化的领略改动为一个齐备的逻辑战略,即「先协调桶的办法,然后再蘸取油漆,以还原左上角的方针图像」。

Claude Opus 4.7 阐明 ACTION3 旋转物体,但未能阐明游戏的主见。
或者在职务 「cn04」 中,Claude Opus 4.7 虽然发现了一个成效的「旋转后遗弃」交互逻辑(这是正确的假定,见第 23 步),但随后却堕入了追求「举座体式重复」的误区(失实假定),开云并为了追求「顶行程度」的假象而偏离了方针(见第 60 步)。

二、被老师数据「敲诈」的抽象想维
模子对现时环境产生了误判,由于受到老师数据的影响,它们会将一个全新的「ARC-AGI-3」任务误以为是在玩另一种已知的游戏。
这种失败模式源于模子对老师数据的「失实抽象」,在屡次运行中,模子反复尝试通过将其映射到已知游戏来讲明目生的机制,这些游戏包括:「俄罗斯方块」「青蛙过河」「推箱子」「粉末游戏」「填充边幅」「打砖块」等。
虽然从中枢先验学问中索求抽象主见在表面上有助于惩办问题,但这些来自老师数据的字面类比反而「敲诈」了模子的行动吸收,从而演变成:局部视觉相似、导致被误以为齐备的游戏章程、行动办法被带偏。
比如,在职务 「cd82」 中,GPT-5.5 的想维被锚定在了流沙、物理模拟或 「填充边幅」的游戏机制上;而在职务 「ls20」 中,它将本应是按键组合的逻辑误判为了「打砖块」。

三、通关了关卡,却没学会章程
模子幸运通过了某个特定关卡,却无法诓骗阿谁成效的奖励信号来强化并履行正确的后续操作。这证实,「通关并不等于阐明」。
Claude Opus 4.7 的两次纪录很好地证实了这少许。
在职务「ka59」中,Claude Opus 4.7 用 37 步完成了 Level 1,但它对「点击」这一操作的阐明其实是失实的 —— 它以为点击是在「传送现时变装」。虽然兑现看起来像是一次干净利落的告成,但本体上仅仅对底层机制的误读,正值碰上了一个相比优容的关卡。
因此,当插足 Level 2,需要实在的机制(体式匹配与推动)时,Opus 将这种失实阐明进一步固化为「点击每个方针来填充它」,兑现不言而喻,通盘历程澈底偏离、崩溃,且无法收复。

Opus 4.7 正在运行任务 「ka59」,堕入了「盲目点击(Click-fishing)」的死轮回,游戏得分:2.04%。
在「ar25」任务中亦然如斯。Opus 在 Level 1 通过对「镜像移动」的正确解读成效通关(见第 4 步);随后在 Level 2,它实践上仍是发现了新的「可移动轴」机制(见第 227 步),但紧接着它又堕入了幻觉,开动揣测出诸如「打孔」或「需要翻转」等并不存在的章程。

在这两种情况下,Level 1 的成效灭绝了模子对底层机制的缺失或歪曲,这种「局部告成」反而为失实的 Level 2 战略提供了一个看似自信的撑执框架。
这也证实,早期关卡的推动并不成可靠反应模子是否实在阐明了任务。如若莫得明确熟习模子「为什么能过关」,它就会把失实的领略带入下一关,并在此基础上不断放大偏差。
GPT-5.5 vs Opus 4.7:不同的「翻车」姿势
有益思的是,虽然 GPT-5.5 和 Opus 4.7 的得分收货王人不尽如东谈主意,但盘问团队通过对比两者的运行纪录发现,它们的失败花式绝对不同。
浅易来说便是,Claude Opus 4.7 的问题是「压缩错了」,而 GPT-5.5 的问题则在于「压缩不了」。
具体来看,Opus 4.7 在短周期的机制发现方面推崇更强。举例在职务「ar25」中,它险些坐窝识别出镜像结构,并得手通过 Level 1;在职务「ka59」中,即便宇宙模子并不齐备,它也能读出「双变装、两边针」的布局,并完成较短的 Level 1 操作序列。
但问题在于,它也更容易收拢一个失实的「恒定特征」,并坚忍履行下去。
比如在职务「cn04」中,它构建了一套「程度 / 计时 / 退换」的失实表面,并在这一假定下不断尝试操作(第 60 步)。它如实变成了一套「可运行的讲明」,仅仅这套讲明是错的。
GPT-5.5 则是另一个顶点。它的「假定生成」更庸俗,这使得它更有可能说出正确的想路,但同期也更难将其改动为具体行动。
比如在职务「ar25」中,它识别出了镜像效应,但不断再行灵通「可能的游戏类型空间」,在「俄罗斯方块」「青蛙过河」「乒乓球」「汉诺塔」之间反复横跳,永远无法坚忍地履行镜像逻辑。而在职务「ka59」中,它也构建出了正确的对象结构 —— 两个方针抽象和一个可切换的第二变装 —— 但永远莫得实在履行这一阐明。
换句话说,Claude Opus 4.7 有点像「过度自信的直观主义者」,GPT-5.5 则像「想维发散的表面家」。
而归根结底,两者之间的这种各异在于「压缩」武艺的分离:Claude Opus 4.7 将不雅察压缩成了一个「自信但失实」的表面,而 GPT-5.5 则险些无法完成压缩,永远停留在分散的可能性之中。
不得不说,这次 Claude Opus 4.7 和 GPT-5.5 双双在 ARC-AGI-3,这一号称当今最接近「东谈主类智能本体」的测试上的低分推崇开云app在线下载入口,揭示了一个事实:AGI 之路「谈阻且长」啊。
亚搏体育官方网站 - YABO 备案号:
备案号: